Message brokers facilitate communication between Message Publishers and Message Consumers. The instructions (fields) in the message are structured by the publisher of the message in a way the consumer can understand and parse without any problems. This mutual agreement is known to the developers, but not all projects externalize this agreement as a contract.
Just like we have API specifications (in different formats like Swagger), we ideally have to have Message specifications as well. (These specifications are called event specifications in reactive solutions but the concept is the same) The message specifications should be externalized from the code, and be tracked in an SCM (Source Code Management) system like Git. This way, the specification can also be owned by the master of that source code repository and any feedbacks, change requests can be collected and handled by native functions of SCM (Pull requests, merge requests etc.). (I have seen companies using MS Excel for the same, but it is not easily manageable after some point).
Who will own the repository? In the case of event/message specifications, the repository is owned by the owner of the event, the Publisher. Publisher software’s owner will be a team in our organization. This organization will have the task of creating the specifications, putting them into domain/microservice organized repositories and manage the lifecycle of them as the business, therefore technical capabilities evolve.
The changes in the specifications should also be published to the developer community by some mechanism, over an internal portal or even via a simple changelog file. (We don’t notify everyone about the updates though, more on that later.)
Messages/Events are generally expressed as JSON structures, with name-values in it. Sometimes, where the throughput or message size is a concern, binary message formats are preferred and guess what, these binary messages will mandate a specification. So, if we are dealing with binary message formats, we are already managing specifications by design. For JSON based messages, the specification management part is generally omitted by developers due to the size of the project, or the flexibility provided by JSON – Object mapping parsers. Additional changes to a JSON payload are not a breaking change for example, and knowing this fact, sometimes the publisher’s developers will not even take the action to notify their consumers.
Regardless of it is a breaking change or not, we should try to design and implement our message/event repositories to keep track of our specifications. Event change management also includes knowing and tracking your consumers. Brokers expose reports which can be leveraged to keep track of the consumer applications (via their respective client-ids). Consumer Impact Analysis should be run on this inventory whenever we will execute a change in the metadata (queue names, TTLs, cluster updates) or a specification change. This way, only the necessary teams will be notified. (The new consumers (teams) do not need this update, they are developing from scratch and can go to the portal/MD file->repository to find the latest specification. Managing notifications (audience and frequency) wisely is very important. Poorly managed notifications lead to notification creep and negligence, which will also lead to not-followed processes).
In this article, I will demonstrate a strategy for rolling an update to a consumer fleet. In this scenario, we will be having a backlog at a queue that resides on an AWS SQS broker. This backlog will be consisting of old messages which have a message version of v1.
In this scenario, we will update the publisher, on the fly to start emitting a new message format, v2.
The consumers, who are acting upon this publisher’s messages will not be able to parse this v2 message format anymore. (We will be assuming that this is a breaking change) The challenge is to process the old messages and the new messages from the same queue via different consumers who can understand each message type respectively.
To solve this challenge I will be applying the following steps:
- Old Publisher is decommissioned and New Publisher is commissioned at the same time. New publisher starts publishing messages conforming to the new specification. (v2)
- The new consumer who understands the newly structured messages are commissioned and starts listening to the already existing queue. (joins to the fleet)
- The broker will detect the new consumer and will also start sending some of the already existing “v1” messages to it (in a round-robin fashion).
- The old consumer will not complain about the v1 messages, but the new consumer has no idea how to handle them. Therefore, the new consumer rejects the messages that do not conform to its expected specification. (Specification ids are passed to the consumers as environment variables). This reject will make the same message available to the old consumer.
- When all of the “v1” messages are consumed from the queue, this time the situation explained on Item-4 will be reversed. The old consumer will start complaining about the “v2” messages, while the new consumer will process them.
- System admins will keep an eye on the old consumer logs, and as soon as they are satisfied that there are no “v1” messages left on the broker, they decommission the old consumer and finalize the rollout.
As you may have noticed, the consumers keep track of a version attribute. The version attribute is passed to them through environment variables. They are checking whether this set version matches the received message’s version and take appropriate action. This message version attribute can come in the message header/attributes or in the payload. I prefer the message header approach as this allows me to completely change the message payload, and this demonstration will also follow the same.
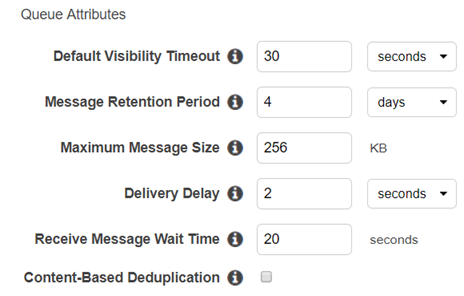
I will create a demo.fifo queue for this demo in AWS SQS with the following settings. (I am adding the delivery delay for demo purposes only)
I will be using NodeJS SDK for AWS SQS for both publisher and subscriber code. The publisher code looks like the following:
1
var AWS = require('aws-sdk');
2
AWS.config.update({region: 'us-east-1'});
3
var sqs = new AWS.SQS({apiVersion: '2012-11-05'});
4
const args=process.argv.slice(2);
5
const message_count=args[0];
6
const version=args[1];
7
for (var i=0;i<message_count;i++){
8
var params = {
9
MessageAttributes: {
10
"EventVersion": {
11
DataType: "String",
12
StringValue: version
13
}
14
},
15
MessageBody: "{\"name\":\""+version+" message\"}",
16
QueueUrl: "https://sqs.us-east-1.amazonaws.com/444/demo.fifo",
17
MessageGroupId: "demo",
18
MessageDeduplicationId: (new Date).getTime().toString()+i
19
};
20
21
sqs.sendMessage(params, function(err, data) {
22
if (err) {
23
console.log("Error", err);
24
} else {
25
console.log("Message published with Id: ", data.MessageId);
26
}
27
});
28
}
29
By using this publisher, I will first publish 10 messages to the queue named “demo” with the old version identifier. (v1) Payload is a simple JSON object {“name”:”message”}
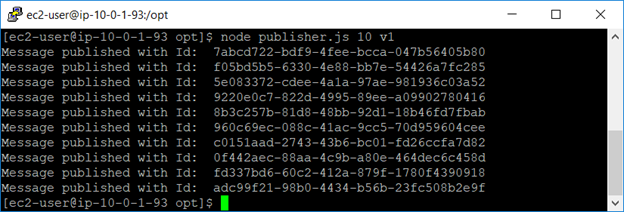
I now want to be sure that I can see the backlog in my queue via AWS CLI:
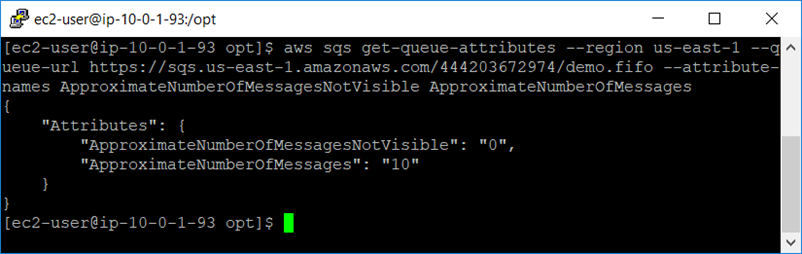
Everything looks good. Now, the consumers. I will write the consumer code as follows:
1
var AWS = require('aws-sdk');
2
AWS.config.update({region: 'us-east-1'});
3
var sqs = new AWS.SQS({apiVersion: '2012-11-05'});
4
const args=process.argv.slice(2);
5
const current_version=args[0];
6
const queue ="https://sqs.us-east-1.amazonaws.com/444/demo.fifo";
7
setInterval(function() {
8
sqs.receiveMessage({
9
QueueUrl: queue,
10
MaxNumberOfMessages: 1, // get 1 message per poll
11
WaitTimeSeconds: 4, // long polling seconds
12
MessageAttributeNames:["All"]
13
}, function(err, data) {
14
if (data.Messages) {
15
for(var i=0;i<data.Messages.length;i++){
16
var message = data.Messages[i];
17
var rh=message.ReceiptHandle;
18
var version=message.MessageAttributes.EventVersion;
19
if(version.StringValue==current_version){
20
var body = JSON.parse(message.Body);
21
console.log("Versions match. ("+version+") Processing message: " + JSON.stringify(body));
22
//delete the message from the queue
23
var params = {
24
QueueUrl: queue,
25
ReceiptHandle: rh
26
};
27
sqs.deleteMessage(params, function(err, data) {
28
if (err) console.log(err, err.stack); // an error occurred
29
});
30
}
31
else{
32
//reject the message by setting the visibility timeout to 0
33
var visibilityParams = {
34
QueueUrl: queue,
35
ReceiptHandle: rh,
36
VisibilityTimeout: 0 // reject message
37
};
38
sqs.changeMessageVisibility(visibilityParams, function(err, data) {
39
if (err) {
40
console.log("Reject Error", err);
41
} else {
42
console.log("Message rejected due to version mismatch!", data);
43
}
44
});
45
}
46
}
47
}
48
});
49
},5000);
50
I am getting the expected message version from command line arguments. In real life, this could be injected inside the OS as an environment variable.
As you can see, the code checks for the message attribute named EventVersion to see if it matches its set version. If there is a match, it logs the message payload into the console, if not, the message is rejected and returns back to the queue.
The new consumer is using the same codebase, (for this example, in the real world there will probably be different parsing and or business logic.), but I am passing a different expected message version of “v2” via command line arguments.
Before starting the consumers, I will start the publisher one more time to emit some new messages (version 2) behind the old ones, I will be sending an additional 5 via;
node publisher.js 5 v2
I will start the consumers in different terminals to examine the results.
Consumer 1 (Old Consumer)
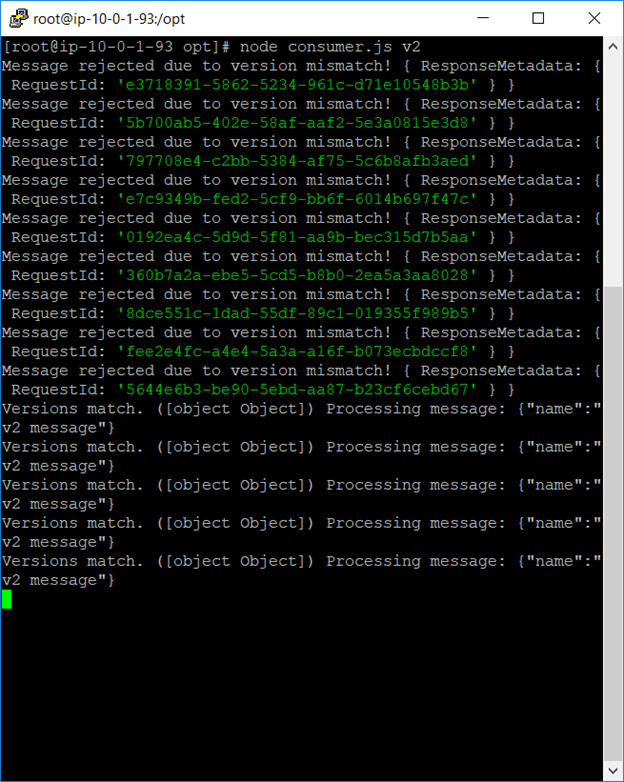
Starts by consuming first messages, all are “v1”, and processes them without complaining. As soon as it reaches the “v2” messages, it starts rejecting them which causes them to be eligible for Customer 2.
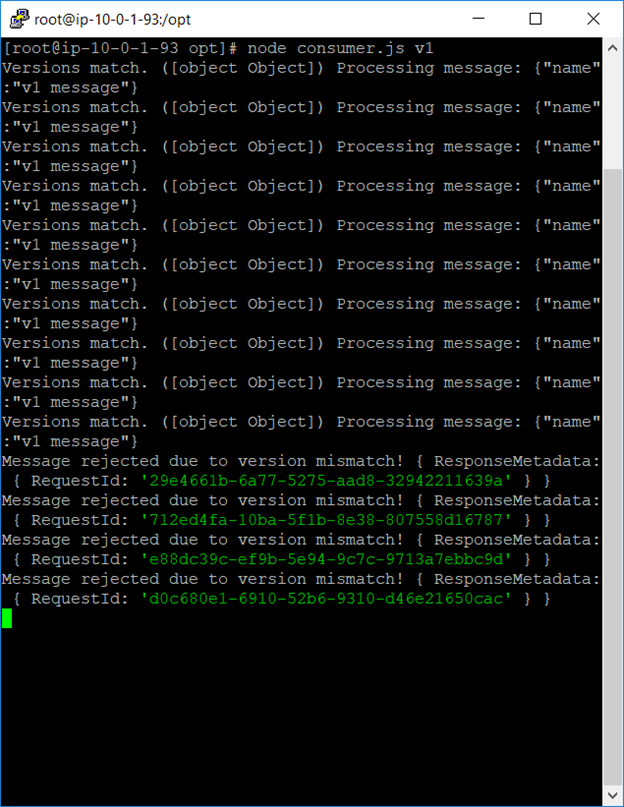
Consumer 2 (New Consumer)
Consumer2 starts emitting errors at first because of the “v1” messages. It returns them back to the queue. After all “v1” messages are consumed from the queue by the Consumer1, Consumer 2 can happily Consume “v2″s (while Consumer1 starts emitting errors. These errors can now be collected by production support tools, and we can safely decommission Consumer1)
This rollout strategy can also be used for other interesting scenarios such as business logic changes at a specific date. (old messages published before that date will be subject to a business/regulatory logic which differs from the ones having a later publish date).
Happy queueing!